最近投篇文章文章到JAFC,要求把转录组数据传到公共数据库,大部分人的选择应当都是传到NCBI了。
记录下我传转录组数据到NCBI的经历,备以后待查。
NCBI数据库地址:https://www.ncbi.nlm.nih.gov/
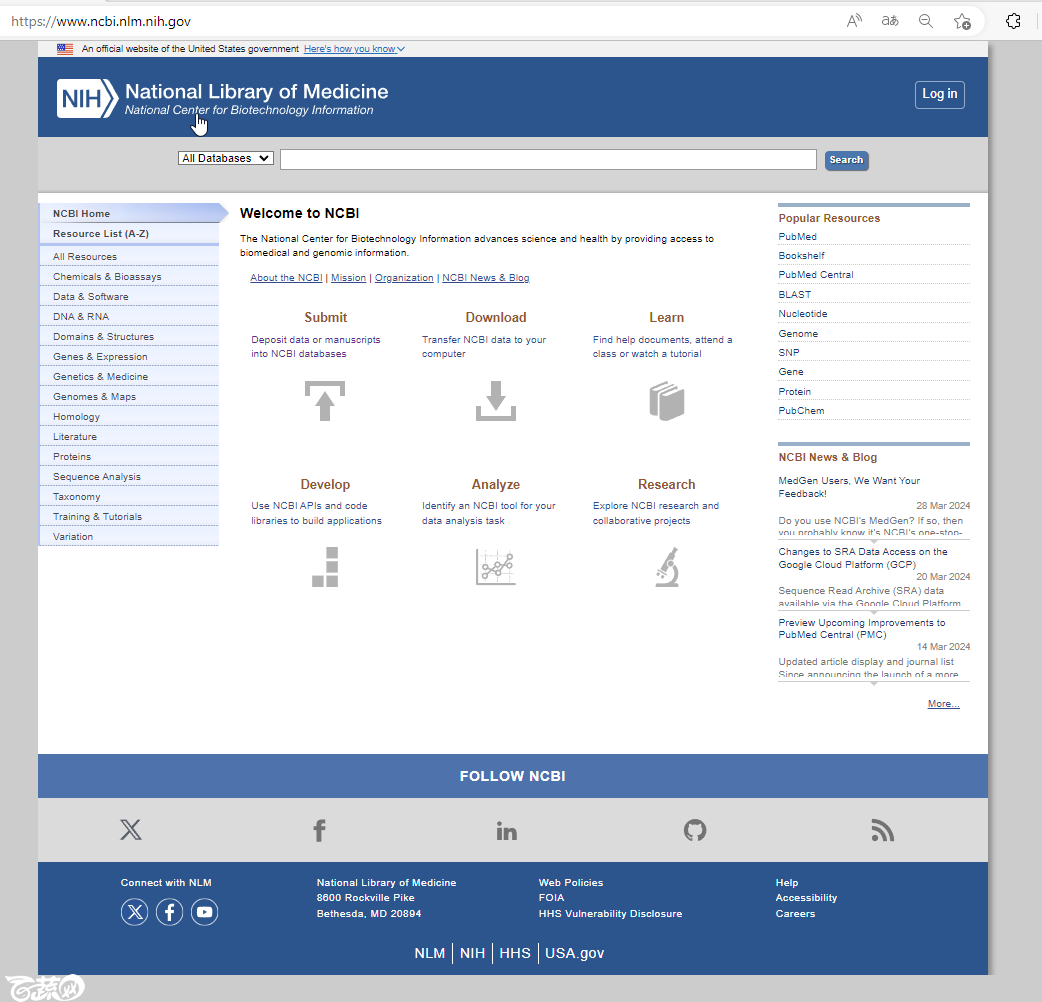
毫无疑问,先自己注册一个账号,我直接使用ORDIC账号登陆。
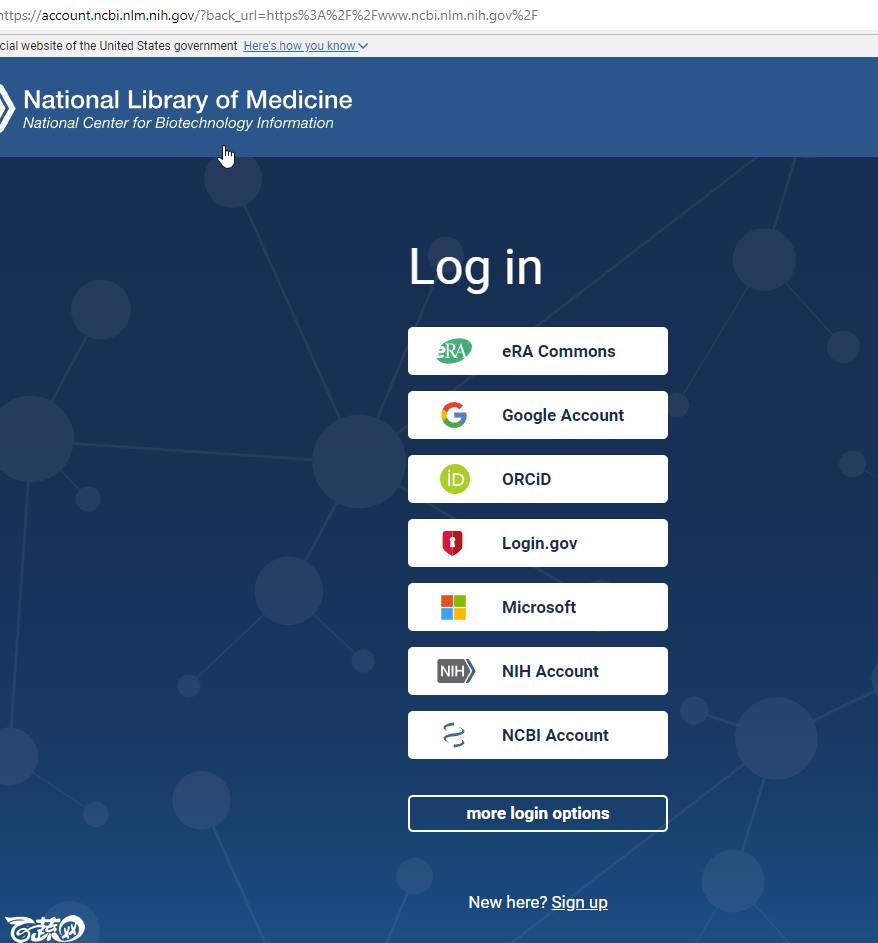
登陆后选择首页的“submit”按钮上传数据。来到“Submission Portal”页面。
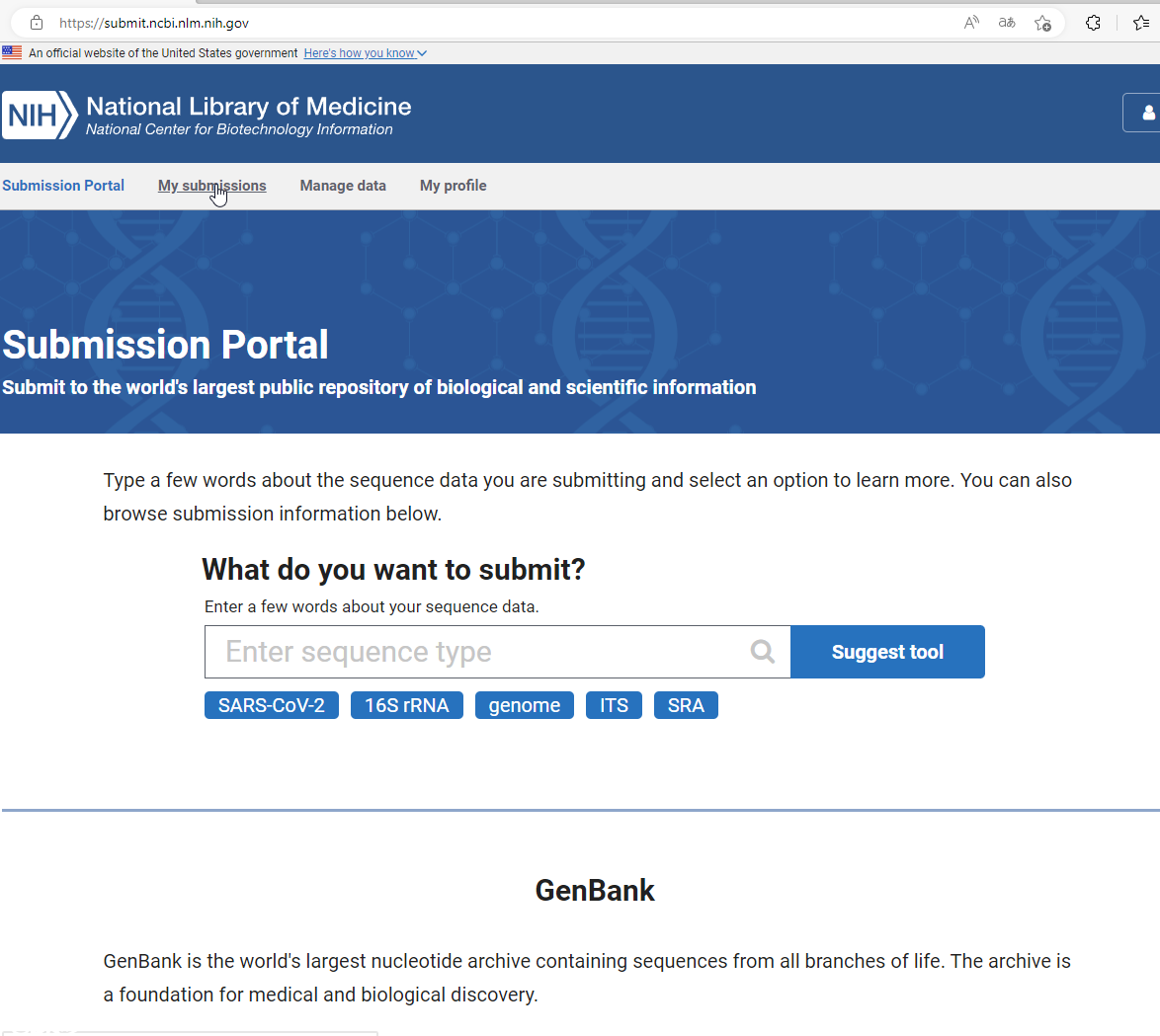
第一次到这个页面,我也是懵的,不知道改选啥。琢磨研究了了一会儿,搞明白了。对于仅仅进行了质量控制,去除含有接头和低质量的Reads的clean data,还没有进行比对组装的原始数据,需要选择“Sequence Read Archive (SRA)”。不用去搜索了,直接把Submission Portal页面往下翻,找到“Sequence Read Archive (SRA),点击里面的Submit即可。
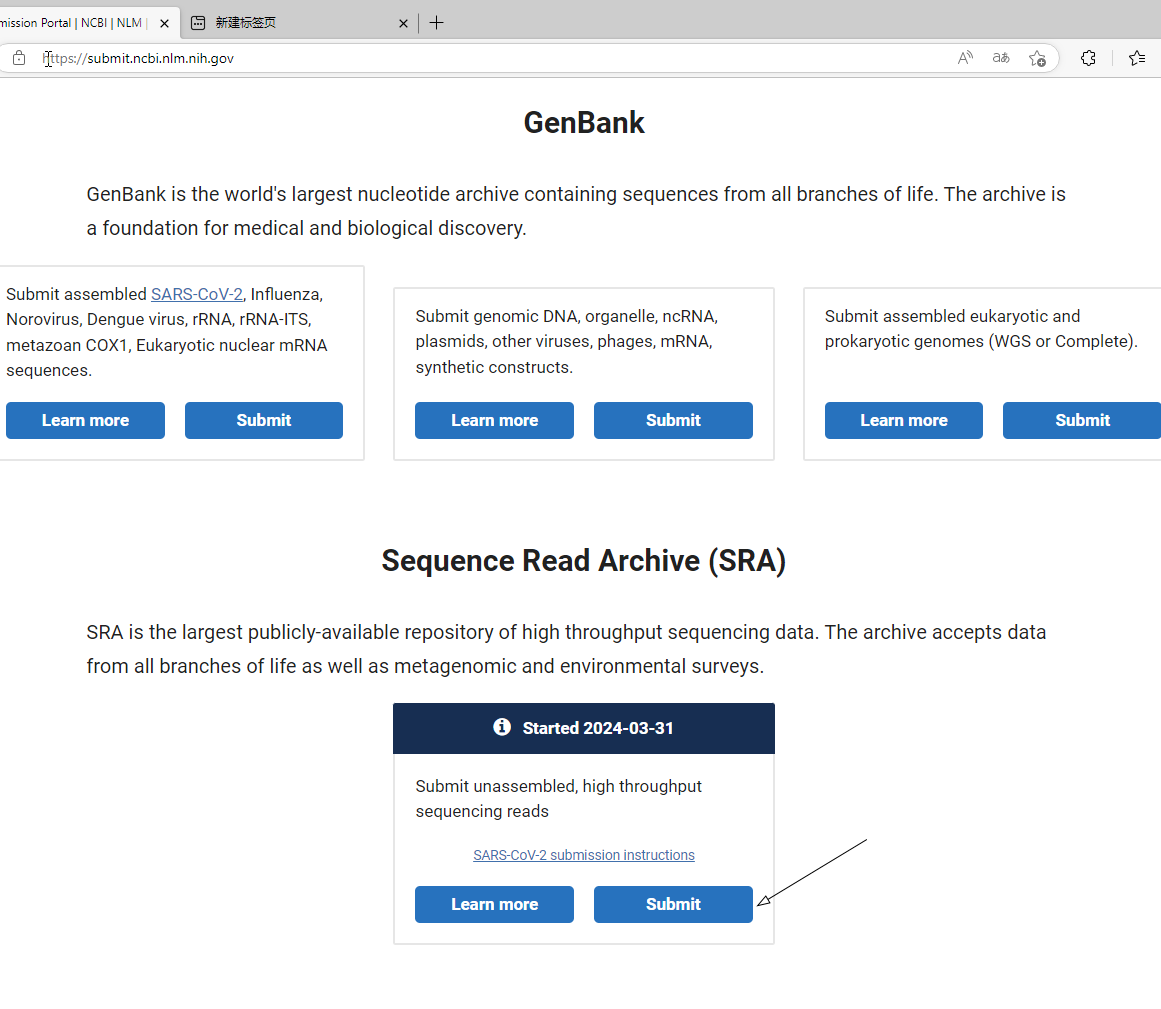
来到SRA的提交页面。
点击”new submission“,第一页是填写submitter的个人信息,第二个是填写“gemeral info”.这里的BioProject
BioProject和BioSample都选择No,程序会自动创建,不需要再额外申请。下面的释放时间,可以自由选择,马上释放或者特定时间释放,都可以。
第三页是Project Info,填写项目情况。”Relevance“是问你测序的目标是农业、工业还是其他行业。
第四页是sample_type,样品类型,是植物、动物还是其他生物。
第五页是attributes,这个是难点,花了我好久时间才搞懂。
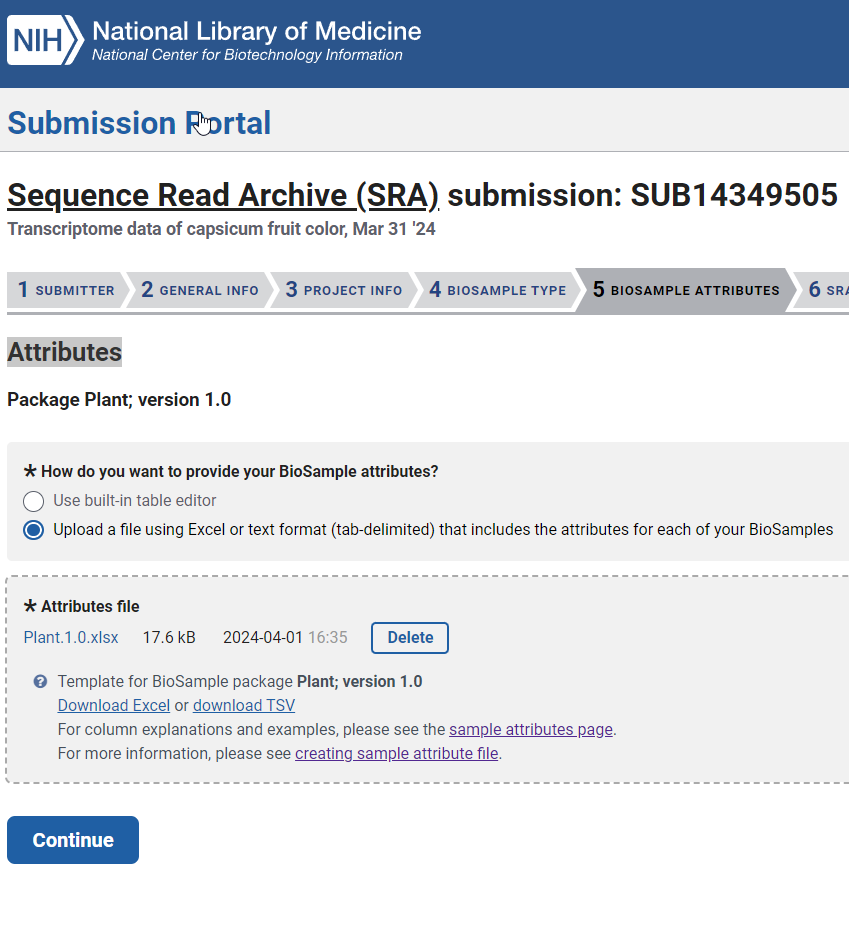
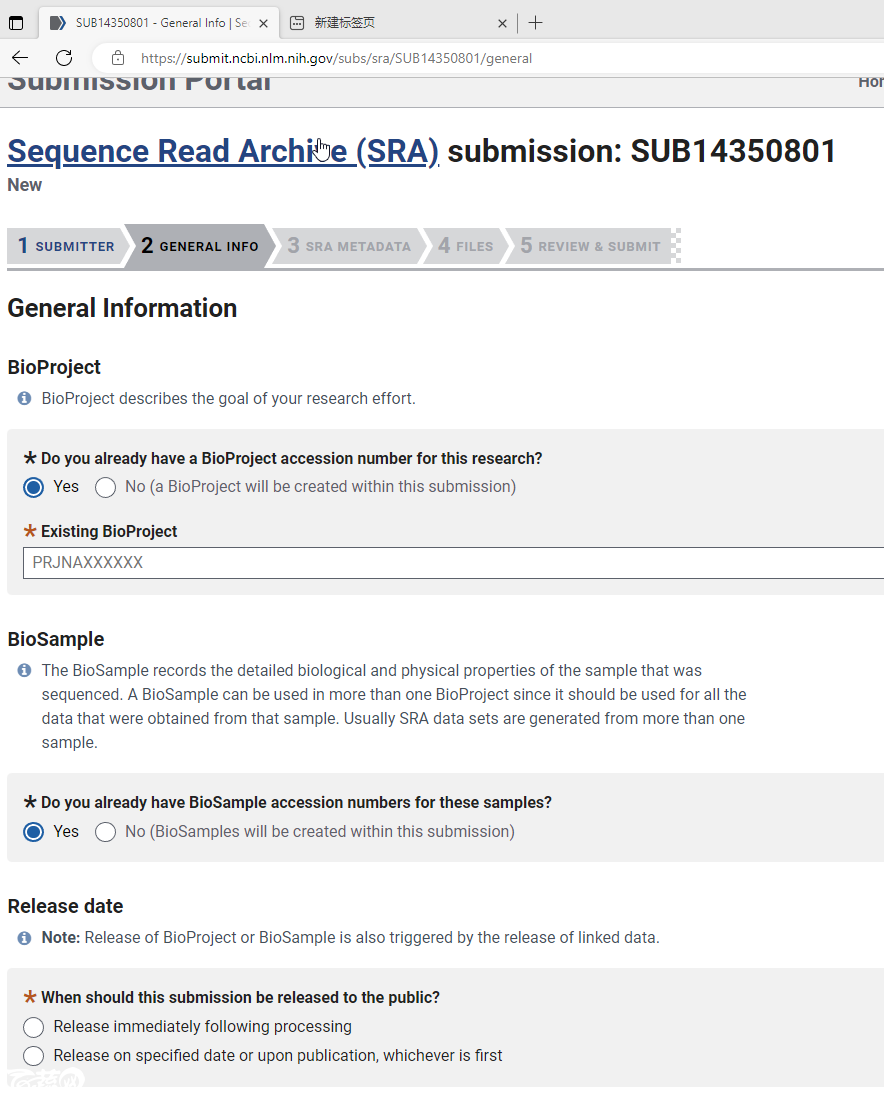
提供样品的属性,我喜欢用第二个,使用Attributes file,在本地编辑完之后,在上传。我是经过无数次的尝试之后才过了这一关,我把我的分享一下
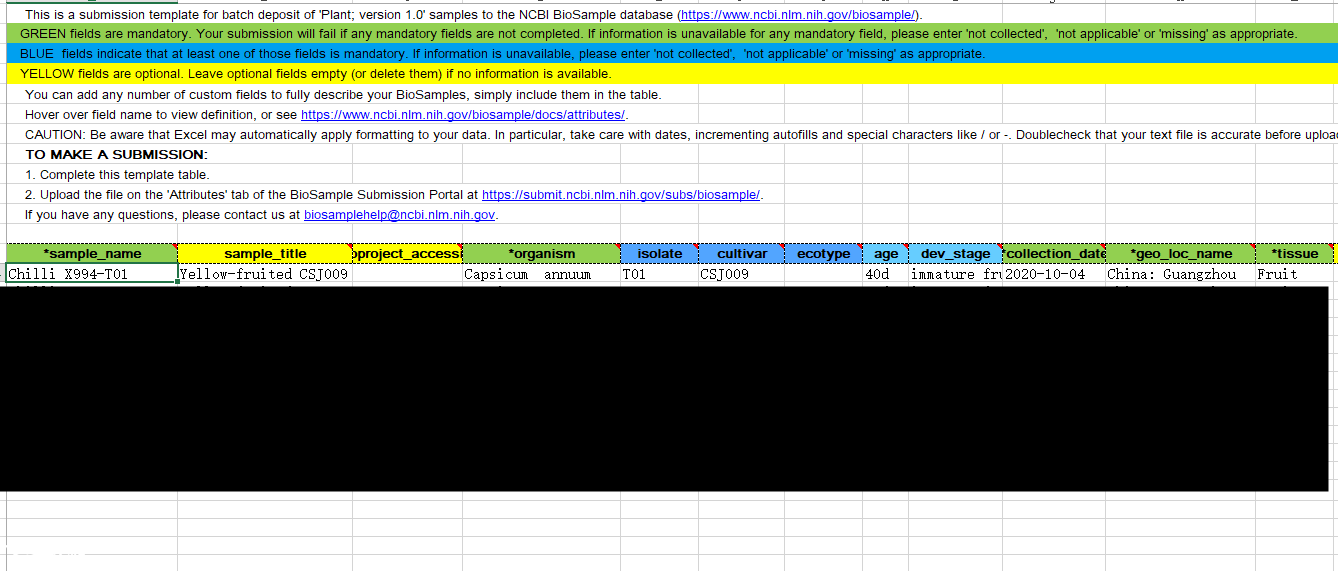
填这个表一定要认真看他们的这个说明,https://submit.ncbi.nlm.nih.gov/biosample/template/?package-0=Plant.1.0&action=definition
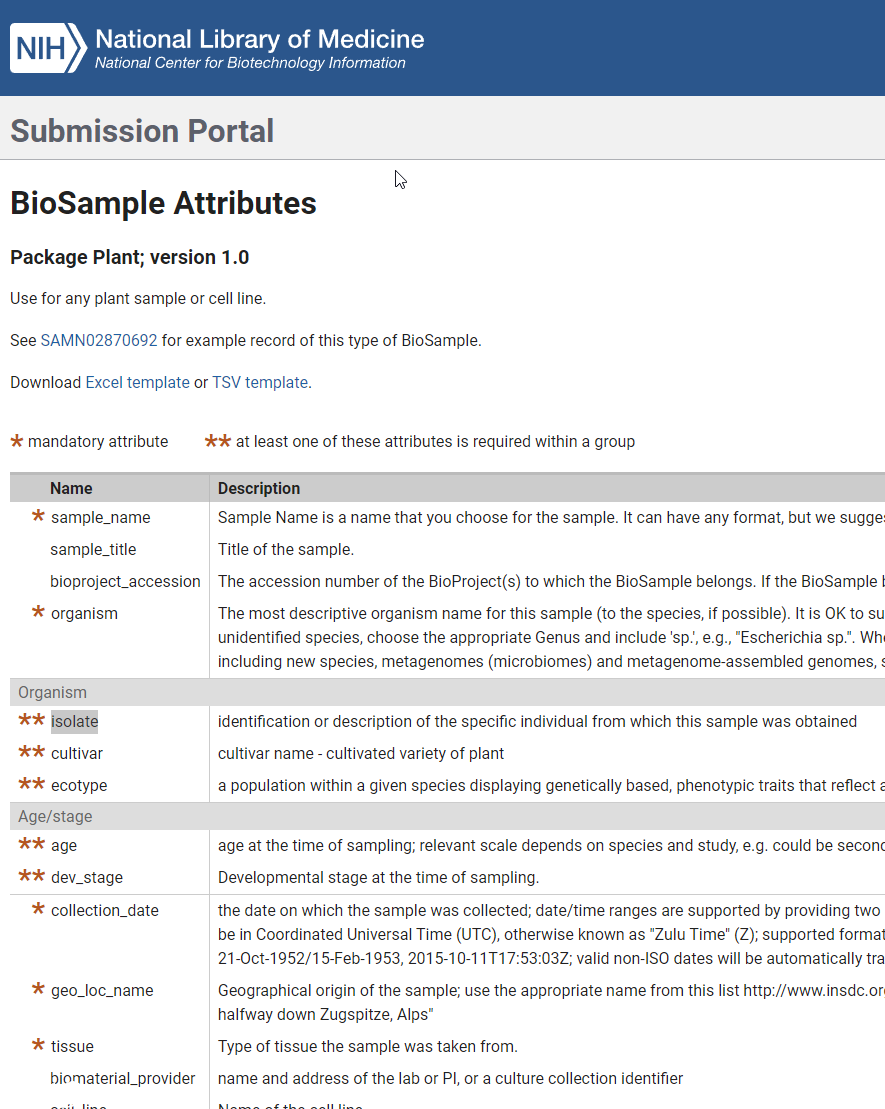
一个星星,那是必填项;两个星星,至少选择一个填写。开始按照说明,只要把绿色的填了就行了,填完了之后发现根本不是那么一回事儿。一直在提示我说有很多行的数据是一致的,可是我的每一行的”sample_name“明明是不同的呀,开始我以为是字符的原因,结果我就用1,2,3,4,5,6这样的name,也是不行,那么很明显,问题不在这里了,往后走,sample_title,三个重复的title肯定是一样的哈。bioproject_accession我全部留空,还没有。organism这里可以在他们数据库查,也可以填自己的。通过多次的尝试,我发现问题在”isolate“,这个是”隔离“意思,他的解释是对获取样本的特定描写,也就是这里一定要明确区分几个样本。
另外,collection_date,geo_loc_name和tissue是必填项,collection_date采集时间,geo_loc_name,采集地点,比如广州。tissue,组织,比如叶片,或者果实等。开始一致通不过,我还填了age,样本时间,dev_stage发育阶段,cultivar,栽培种名,最后总算是过了。
来到第六页,SRA METADATA,这里我还是选择本地编辑SRA_metadata文件,然后上传。我也分析一下。
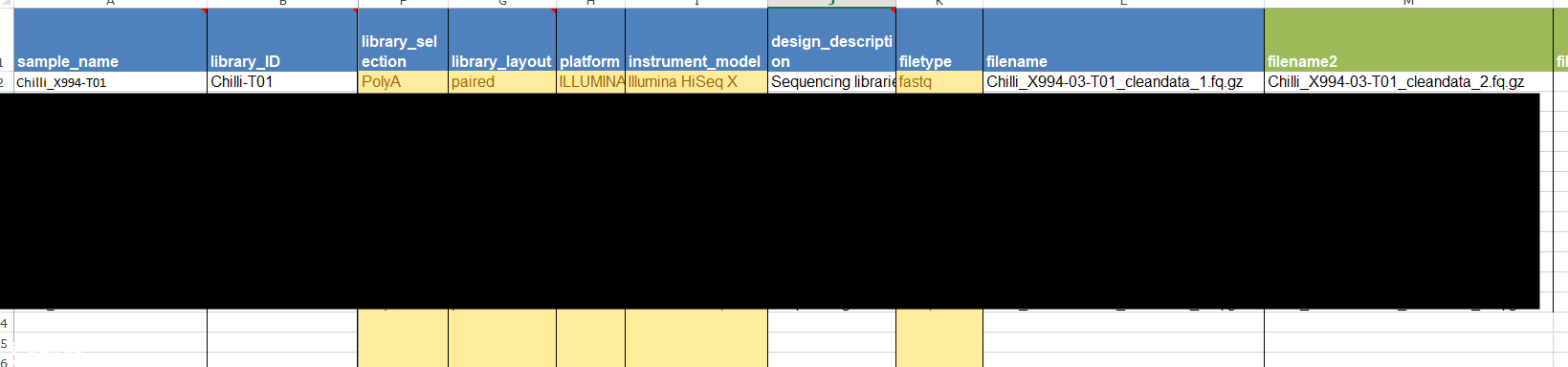
sample_name和library_ID每个不同就行,library_selection,建库方法,一般是PolyA,layout形式是双端测序paired,platform测序平台,我的是ILLUMINA,instrument_model具体设备型号是Illumina HiSeq X。design_description这个就是构库的方法。filetype文件类型一般是fastq. 如果前面layout选择了paired,那么后面的filename就应当是2个相对应的数据,并且这里的filename需要和上传的文件名完全吻合,不建议使用特殊字符赖命名文件,不然出现各种错误。
第七页是files,文件上传。
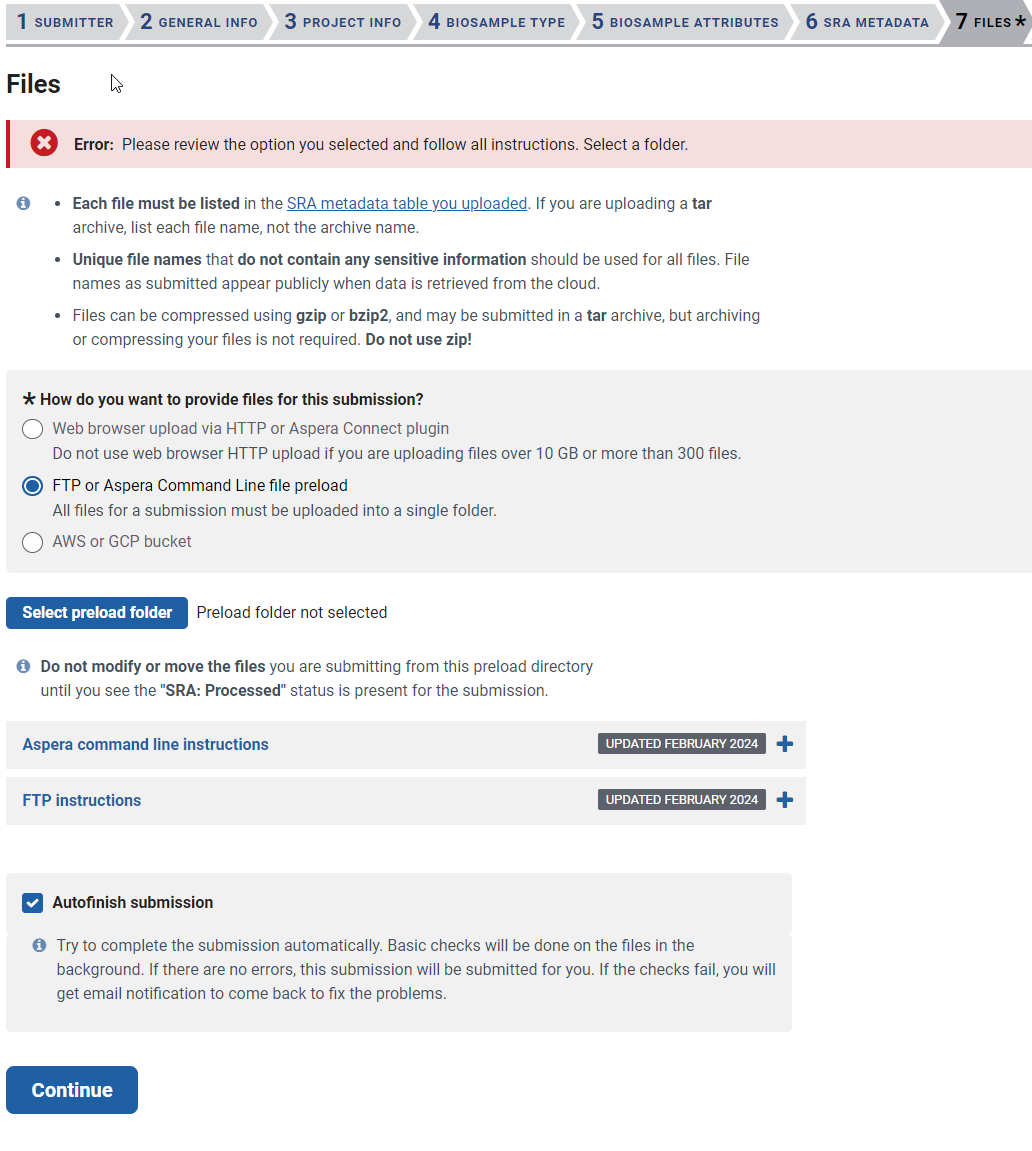
这里询问上传文件的方式,第一种就是通过浏览器上传,不推荐。第二种是通过FTP软件或者ASPERA命令上传,ASPERA的浏览器插件和命令行可能效果也不过,我看有人推荐过。我个人喜欢FTP,主要是可以续传,丢在FTP里面就不管了。
怎么传呢。他这个FTP instructions里面有详细介绍,来看看
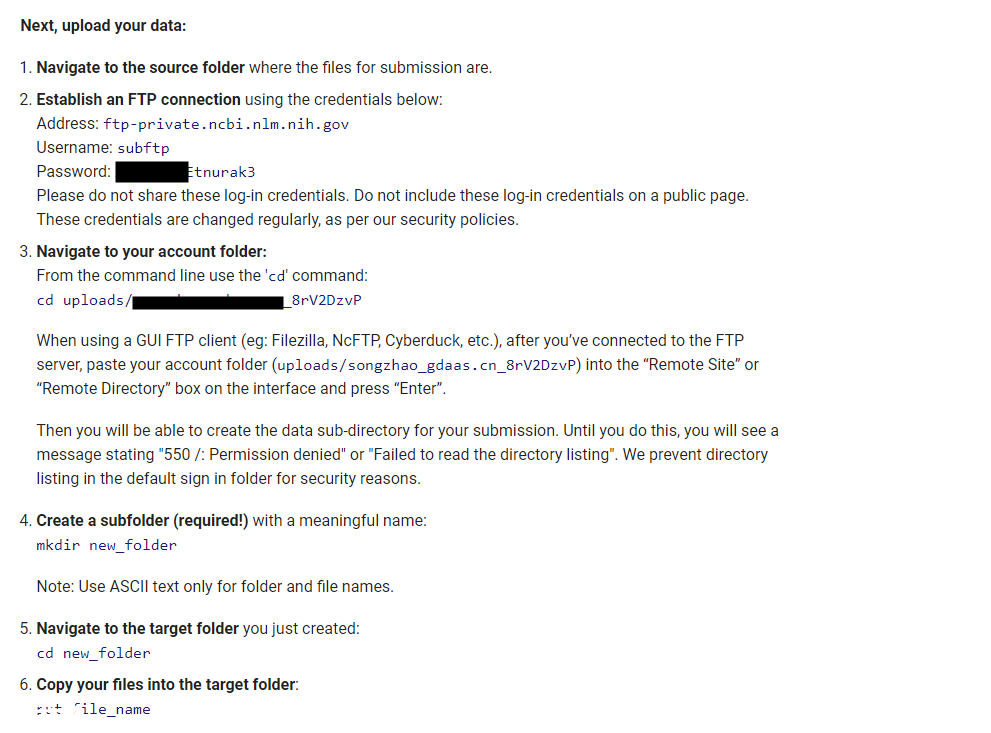
这里有两个关键点,1,提供了路径和账号,地址是ftp-private.ncbi.nlm.nih.gov,用户名是subftp,和相应的密码。2,传到哪个位置呢,不是根目录,而是一个临时次级目录,比如我这里是uploads/cn_8rV2DzvP,因人而异。这里要提醒一点的是这个目录在CuteFTP连接后看不到,需要手动输入这个路径,然后上传我们的cleandata就ok啦。全部传完之后,这些数据就会出现在第七页的preload folder这里,可供选择啦。
转载请注明:百蔬君 » 【原创文章】上传转录组测序原始数据到NCBI的详细攻略